Datasets - How Neural Machine Translation Works
I’m currently working on training client-side translation models for Firefox. These models are small distilled models that can be reasonably downloaded by our users, and run directly on their machines using the CPU. In this article I’m going to explain from a high level how machine translations works.
The data
In order for a translation model to begin learning, it first needs data–a lot of data. This data comes in the form of “sentence pairs”. A “sentence” in this pair could be a paragraph, or a sentence fragment. It is a finite chunk of text that has both sides of a translation. Various datasets use different strategies to gather these sentences. Some are professionally translated. Other types of datasets are “mined” from the internet in order to find what is known as “parallel data”, or documents that are the same, but are in different languages.
Here are some actual examples of sentence pairs sampled from the NLLB dataset:
English: From your lofty halls You refresh the mountains;
Spanish: De Tus altas moradas, Tú riegas las montañas,English: Is this a better chance for you or Ortiz?
Spanish: ¿Es esto una mejor oportunidad para usted o para Ortiz?English: He did it all as evidence that My Grace was in his heart.”
Spanish: Él hizo todo eso como evidencia de que mi gracia estaba en su corazón”.English: An era of accountability for Facebook and other monopolies may be beginning.
Spanish: Una era de responsabilidad para Facebook y otros monopolios puede estar comenzando.English: There are certain things you take liberty with.”
Spanish: Hay ciertas cosas con las que tomas libertad”.
For the Firefox models, we are heavily relying on the OPUS project for finding datasets for training. It is a fantastic tool that categorizes and serves up datasets specifically for machine translation. The datasets all come from different sources, so care is needed to use them correctly or at least have good filtering and data cleaning to ensure high quality results. We have other places to find datasets, like Hugging Face, but the queries there have not been curated and datasets aren’t normalized for easy gathering.
How much data is needed
As I alluded to earlier, a lot of data is needed for generating good machine models. In the literature, it’s frequently cited that a large amount of data is in the range of millions of sentence pairs. We have found that training production-ready models requires significantly more data. Our team decided on the following breakdown for data size and model quality categories. This was a practical decision on how to talk about training 100 language pairs, and wasn’t rigorously deduced. Keep in mind that we are training general translation models that have to be robust across many different domains of knowledge.
| Size Category | Sentence Pairs |
|---|---|
| High Resource | > 80 million |
| Medium Resource | 20 - 80 million |
| Low Resource | < 20 million |
Some examples of high resource languages would be Spanish (600 million), French (500 million), German (~350 million). In the medium resource range we have languages such as Slovenian (72 million), Catalan (23 million), Farsi 38 million. In the low resource range we have Galician (14 million), Georgian (14 million), Icelandic (14 million).
How datasets are built
There are various strategies for building datasets. I will go through a few of them.
The United Nations
To start off, there is sometimes the case that professional translators will translate a single corpus (body of work) into multiple languages. United Nations’ official documents are translated into its six official languages The MultiUN project took these documents, and built a parallel corpus out of this.
There are six official languages of the UN. These are Arabic, Chinese, English, French, Russian and Spanish. The correct interpretation and translation of these six languages, in both spoken and written form, is very important to the work of the Organization, because this enables clear and concise communication on issues of global importance.
Here is a sample from this dataset:
English: As a new element, UNIDO’s contribution to the language and documentation services (UNOV) has been added to this Major Programme.
Spanish: Como elemento nuevo, se ha agregado a este programa principal la contribución de la ONUDI a los servicios de idiomas y documentación (ONUV).English: Further details are included in the chapter entitled “Budget Framework”.
Spanish: En el capítulo titulado “Marco presupuestario” figuran más detalles al respecto.English: RPTC and Special Resources for Africa
Spanish: POCT y recursos especiales para ÁfricaEnglish: As in the biennium 2004-2005, the entire volume of the funds dedicated to the Regular Programme of Technical Cooperation will be freely programmable in 2006-2007.
Spanish: Al igual que en el bienio 2004-2005, la totalidad de los fondos que se dedicaban al programa ordinario de cooperación técnica se podrán programar libremente en 2006-2007.
This data is professionally translated, and high quality. However, the language in it is quite formal and would not be represented when translating certain “domains” of text. For instance, a model trained on just this data would struggle with social media posts, or translating a novel, but the model would be great for translating official government documents. This dataset is 11 million sentences for English and Spanish parallel sentences. This is about half the data needed for getting a language into our “Medium Resource” range. The main limitation is that these documents represent only six languages.
Open Subtitles
Much of the web is built on crowd-sourced data. Some of this data is already in the form of parallel sentence data. Subtitles are naturally in this form and are distributed as .srt files. The .srt files include both the text that is being spoken, and a timestamp that can be used to match up parallel sentences. A dump from 2016 of OpenSubtitles.org was used to build a training set. While the United Nations language was very formal, subtitles contain a huge amount of casual language. This type of data helps make a language model more robust across various domains. The problem though, is that these subtitles are user generated. They can’t be used directly without a lot of filtering, de-duplication, and cleaning.
From their paper, this graphic shows the processing pipeline for building the dataset.
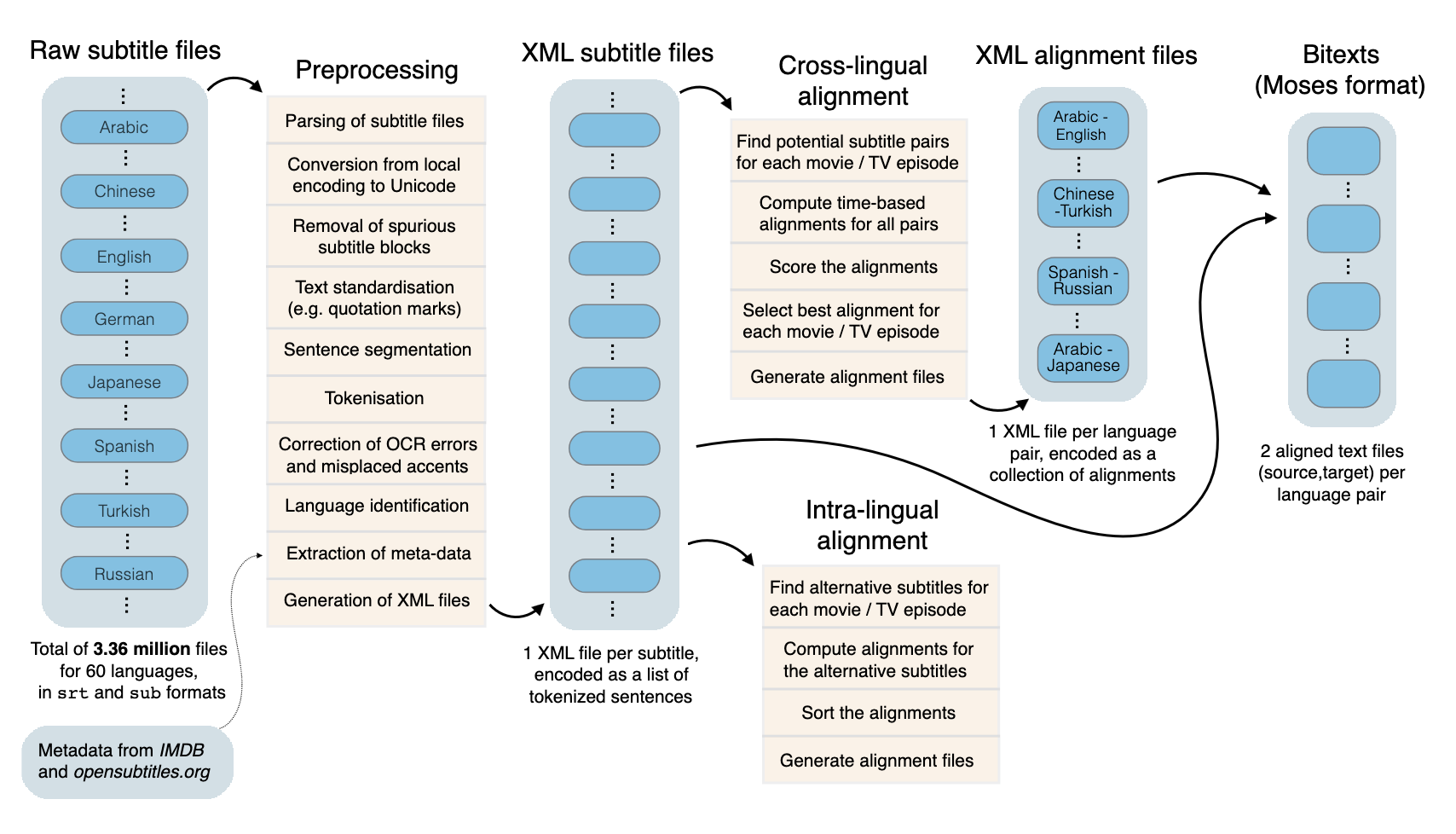
And this is an example of the .srt format they are processing:
5
00:01:15,200 --> 00:01:20,764
Nehmt die Halme, schlagt sie oben ab,
entfernt die Bl¨atter
6
00:01:21,120 --> 00:01:24,090
und werft alles auf einen Haufen
f¨ur den Pflanztrupp.
7
00:01:24,880 --> 00:01:30,489
Das Zuckerrohr beißt euch nicht.
Nicht so zaghaft! Na los, Burschen, los!The sentences from different files are aligned using a combination of timing information and word alignment information. Here is an example from the Spanish
English: What happened?
Spanish: ¿Qué sucedió?English: - What is wrong?
Spanish: ¿ Qué ocurre?English: - Get away from her !
Spanish: ¡ Aléjate de ella !English: - What happened ?
Spanish: - ¿ Qué sucedió ?English: - Get away from her !
Spanish: - ¡ Aléjate de ella !English: Call an ambulance .
Spanish: Llama a una ambulancia .
Data mining the entire web
The next class of datasets is probably the most valuable for training a language model that is to be used for translating the web. These datasets are built from snapshots of the web that generally come from the Common Crawl project. This is a 501(c)(3) non-profit that actively collects snapshots of the web. At the time of this writing, there have been over 250 billion pages in their snapshots spanning 17 years. Their active scraping is adding 3-5 billion new pages a month. My humble website is most likely represented in this crawl.
The question then is, given a big pile of documents, how do you process them to find parallel sentences? There are many different strategies, but I’ll describe briefly how the CCMatrix dataset and No Language Left Behind (NLLB) dataset were generated. CCMatrix was the first iteration, and then Meta researchers continued their work with NLLB.
The web is made up of HTML and is messy.
Step 1: Clean the data – CommonCrawl pages are full of markup and must be cleaned. They need to be converted into plain text. The markup includes many duplicated pieces of text such as headers and footers. These must be scrubbed to only include the relevant content of the pages. The data is then grouped into individual “paragraphs” of text. These paragraphs are chunks of text that may include a variety of lengths of texts, multiple sentences, one sentence, or just fragments of text.
Step 2: Train a language identification model – If you are able to find documents that are all reliably in a single language, you can train a language model that can predict what language the document is in. Examples of these monolingual datasets could be Wikipedia, which is reliably translated into a variety of languages, or the Christian Bible, which is available in many different language. The language ID model is then trained on this labeled data to predict the probability that a given document, paragraph, or sentence is in a specific language. NLLB used fastText which is another Meta project.
Step 3: Split the data by language – The language identification model was then used to split the cleaned CommonCrawl data into different buckets based on the language. At this scale, tasks are parallelized to run on multiple cloud machines for efficient processing. Each paragraph was run through a language detector, then a sentence splitter based on the language, and each sentence was run through a language detector again. If the sentence doesn’t match, it is discarded. This approach leads to a splitting of the data where there is a higher confidence that the paragraphs and sentences are in the language.
Step 4: Embed the paragraphs – Next paragraphs can be embedded into a learned multilingual embedding space to match up text that has similar meaning. This is done by training a multilingual language model. As text is encoded by the model producing an embedding. This embedding is a vector. These vectors can then use cosine similarity to compare how close they are to each other. Text that shares really close cosine similarity values will be text that is aligned and has the same meaning. The massive step that requires hugely parallel workloads is to embed all of the paragraph data. These embeddings are generated, and stored in a datastore that is then queried to find all the paragraphs that match their meaning. NLLB used an improved LASER model called LASER3 to accomplish this.
Bitext mining
These steps ultimately lead to identifying and grouping paragraphs and sentences of different types from all across the web into a single unified dataset of parallel text. This process is called “bitext mining”. This is done at such a large scale that huge amounts of data are produced. This data can then be a cornerstone for training language models.
NLLB contains 13,000,000,000 (13B) sentences. On their own these sentences represent monolingual data, of which 34% of these sentences are in English. However, these sentences can be matched up in different parallel combinations, which is the primary data used to build a translation model.
Here are examples of some high resource languages.
| Language | Monolingual Sentences | Language Pair | Parallel Sentences |
|---|---|---|---|
| English | 4.3 B | ||
| Spanish | 2.1 B | English - Spanish | 409 M |
| French | 1.9 B | English - French | 329 M |
| German | 1.3 B | English - German | 247 M |
Using examples from above, here are some lower resource languages:
| Language | Monolingual Sentences | Language Pair | Parallel Sentences |
|---|---|---|---|
| Galician | 172M | English - Galician | 13M |
| Icelandic | 19M | English - Icelandic | 9M |
| Georgian | 15M | English - Georgian | 11M |
You have data, now what?
Just getting the datasets and understanding how they were generated is a first step. After that it’s important to combine, deduplicate, and clean the data. Some datasets come in cleaner than others, and data can also be duplicated. For instance, using a cleaner that uses something sentence similarity based on embeddings wouldn’t make sense to apply to a dataset like NLLB where a similar strategy was already used. But it may make sense to use it for a dataset like OpenSubtitles where the matching strategy that was used to generate the dataset was different.
Other topics that can be explored from here are data cleaning, filtering, and augmentation. There are many challenges in data preparation. Datasets can be poorly aligned, contain strange charactrs, or do things like translate currencies.
It is also useful to see how parallel data and monolingual data can be used in combination for training using backtranslations. Getting the data is just the first step, but it’s one of the important ones to training language models.