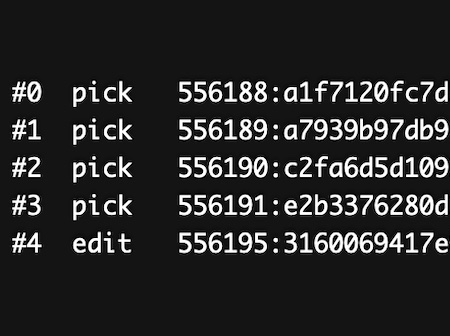
Documenting Regex with ASCII Art
// ____ ______
// / __ \ ___ ____ _ / ____/ _ __
// / /_/ / / _ \ / __ `/ / __/ | |/_/
// / _, _/ / __/ / /_/ / / /___ _> <
// /_/ |_| \___/ \__, / /_____/ /_/|_|
// /____/
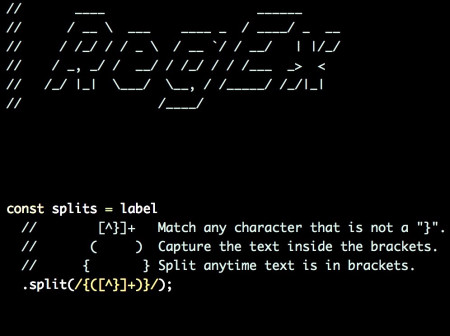
const splits = label
// [^}]+ Match any character that is not a "}".
// ( ) Capture the text inside the brackets.
// { } Split anytime text is in brackets.
.split(/{([^}]+)}/);
Generating my own ASCII art in programming projects is a great way to solve certain hard problems. Diagrams made from PNGs with some kind of rendered documentation is great, but it has a high barrier to entry. Plus, this kind of documentation does not live with the code, which makes it easy to miss and forget about. I am going to start a series of posts detailing various strategies on how I draw with ASCII.
Regular Expressions
Regexes are quite difficult to maintain. They are dense, don’t break apart separately, and use a custom hard-to-learn language based off of funky characters. Almost every time that I encounter one in a code review, I take pause and add some feedback to document and test it better.
The following is a regex that I wrote to split out groups of matching curly braces, in order to replace this text with custom values. As is common, this feature started out fairly simple, and then grew more and more complicated.
I’ve struggled in the past with documenting regexes, and I was quite happy with this result. While this article does not demonstrate strict ASCII art, I think it’s still a valid example of using white space and unconventional formatting to increase the maintainability of code.
const splits = label
// Split out all text surrounding by curly braces
//
// e.g. "{example}"
// => ["" "example"];
// "With text: {example}"
// => ["With text: ", "example"];
// "With {multiple} examples of {text}"
// => ["With " "multiple", " examples of ", "text"];
//
// [^}]+ Match any character that is not a "}".
// ( ) Capture the text inside the brackets.
// { } Split anytime text is in brackets.
.split(/{([^}]+)}/);
This quite nicely captures the idea of what the regex is doing. Here is another example from parsing a URL parameter for a range of times.
const matches = committedRange
// This regexp captures two (positive or negative) numbers, separated by a `_`.
//
// [0-9.]+ [0-9.]+ Match any combination of numbers and periods
// -? -? Match an optionally negative number
// ( )_( ) Create two capture groups separated by an underscore.
// ^ $ Match the start and end
.match(/^(-?[0-9.]+)_(-?[0-9.]+)$/);
// Now check for a non-null result, and that the numbers are not NaN.
I found another undocumented regex in the Firefox Profiler and tried out this technique. I had no idea what the regex did without plugging it into regexr.com and pondering over it. As a reviewer, it’s also really hard to double check the intent and correctness of a regex without proper documentation.
const result = pathInZipFile
// Get the file name in a zip file path
// e.g. "path/to/file.txt" -> ["file.txt"]
// "file.txt" -> ["file"]
//
// [^/]+ Match all the rest of the characters that aren't "/"
// \/ Match a single forward slash "/"
// [^/]+ Match one or more character, as long as it's not "/"
// (?: )? Non-capturing group, which is optional.
// / $/ Match starting anywhere, to the end.
.match(/(?:[^/]+\/)?[^/]+$/);
Thanks to patorjk.com for the initial ASCII header text in my story’s graphic.